Beginning with MySQL 5.1.18, it is possible to use MySQL Cluster in multi-master replication, including circular replication between a number of MySQL Clusters.
Note
Prior to MySQL 5.1.18, multi-master replication including circular replication was not supported with MySQL Cluster replication. This was because log events created in a particular MySQL Cluster were wrongly tagged with the server ID of the master rather than the server ID of the originating server.
Circular replication example. In the next few paragraphs we consider the example of a replication setup involving three MySQL Clusters numbered 1, 2, and 3, in which Cluster 1 acts as the replication master for Cluster 2, Cluster 2 acts as the master for Cluster 3, and Cluster 3 acts as the master for Cluster 1. Each cluster has two SQL nodes, with SQL nodes A and B belonging to Cluster 1, SQL nodes C and D belonging to Cluster 2, and SQL nodes E and F belonging to Cluster 3.
Circular replication using these clusters is supported as long as:
The SQL nodes on all masters and slaves are the same
All SQL nodes acting as replication masters and slaves are started using the
--log-slave-updatesoption
This type of circular replication setup is shown in the following diagram:
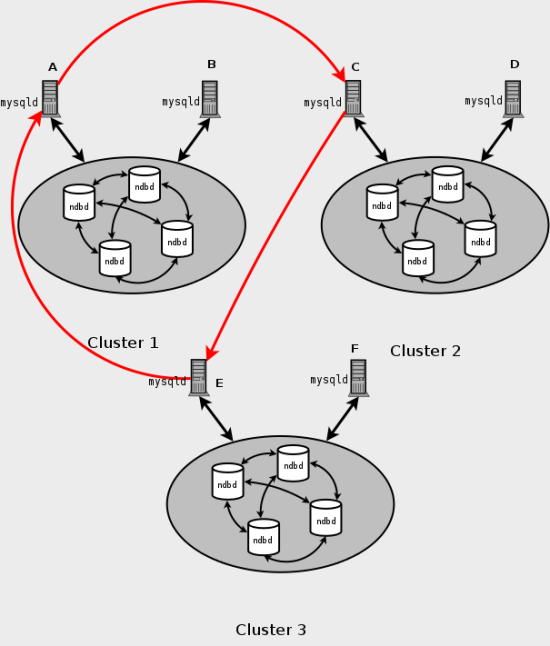
In this scenario, SQL node A in Cluster 1 replicates to SQL node C in Cluster 2; SQL node C replicates to SQL node E in Cluster 3; SQL node E replicates to SQL node A. In other words, the replication line (indicated by the red arrows in the diagram) directly connects all SQL nodes used as replication masters and slaves.
It is also possible to set up circular replication in such a way that not all master SQL nodes are also slaves, as shown here:
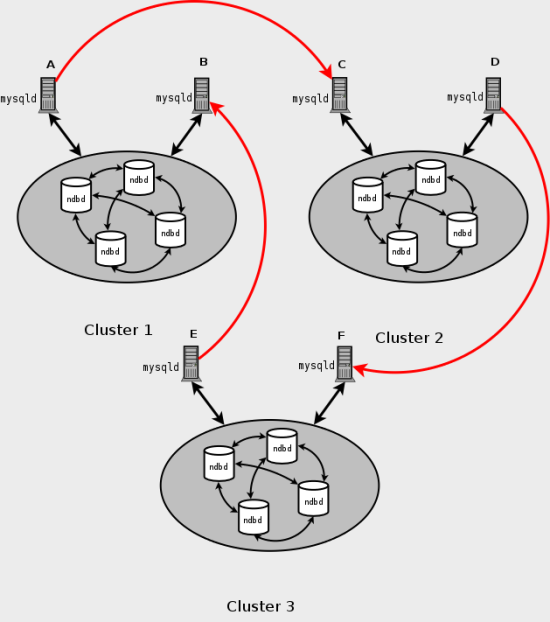
In this case, different SQL nodes in each cluster are used as
replication masters and slaves. However, you must
not start any of the SQL nodes using
--log-slave-updates (see the
description of
this option for more information). This type of circular
replication scheme for MySQL Cluster, in which the line of
replication (again indicated by the red arrows in the diagram) is
discontinuous, should be possible, but it should be noted that it
has not yet been thoroughly tested and must therefore still be
considered experimental.
Important
Beginning with MySQL 5.1.24, you should execute the following statement before starting circular replication:
mysql> SET GLOBAL SLAVE_EXEC_MODE = 'IDEMPOTENT';
This is necessary to suppress duplicate-key and other errors
that otherwise break circular replication in MySQL Cluster.
IDEMPOTENT mode is also required for
multi-master replication when using MySQL Cluster. (Bug#31609)
See slave_exec_mode, for more
information.
Using NDB-native backup and restore to initialize a slave MySQL Cluster.
When setting up circular replication, it is possible to
initialize the slave cluster by using the management client
BACKUP command on one MySQL Cluster to create
a backup and then applying this backup on another MySQL Cluster
using ndb_restore. However, this does not
automatically create binary logs on the second MySQL
Cluster's SQL node acting as the replication slave. In
order to cause the binary logs to be created, you must issue a
SHOW TABLES statement on that SQL
node; this should be done prior to running
START SLAVE.
This is a known issue which we intend to address in a future release.
Multi-master failover example. In this section, we discuss failover in a multi-master MySQL Cluster replication setup with three MySQL Clusters having server IDs 1, 2, and 3. In this scenario, Cluster 1 replicates to Clusters 2 and 3; Cluster 2 also replicates to Cluster 3. This relationship is shown here:
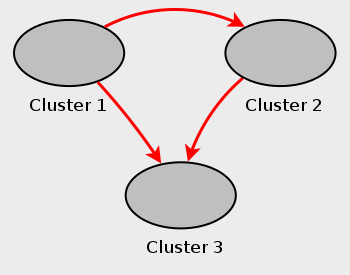
In other words, data replicates from Cluster 1 to Cluster 3 via 2 different routes: directly, and by way of Cluster 2.
Not all MySQL servers taking part in multi-master replication must act as both master and slave, and a given MySQL Cluster might use different SQL nodes for diffferent replication channels. Such a case is shown here:
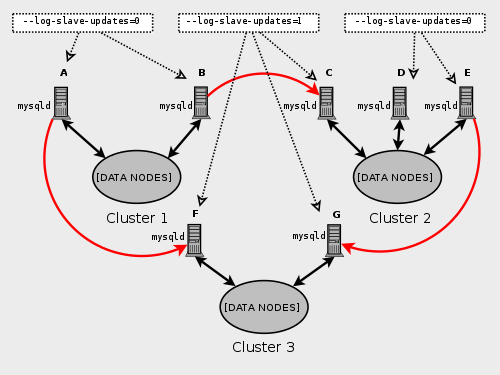
MySQL servers acting as replication slaves must be run with the
--log-slave-updates option. Which
mysqld processes require this option is also
shown in the preceding diagram.
Note
Using the --log-slave-updates option has
no effect on servers not being run as replication slaves.
The need for failover arises when one of the replicating clusters goes down. In this example, we consider the case where Cluster 1 is lost to service, and so Cluster 3 loses 2 sources of updates from Cluster 1. Because replication between MySQL Clusters is asynchronous, there is no guarantee that Cluster 3's updates originating directly from Cluster 1 are more recent than those received via Cluster 2. You can handle this by ensuring that Cluster 3 catches up to Cluster 2 with regard to updates from Cluster 1. In terms of MySQL servers, this means that you need to replicate any outstanding updates from MySQL server C to server F.
On server C, perform the following queries:
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;
Copy over the values for @file and
@pos manually from server C to server F
(or have your application perform the equivalent). Then, on server
F, execute the following CHANGE MASTER
TO statement:
mysqlF> CHANGE MASTER TO
-> MASTER_HOST = 'serverC'
-> MASTER_LOG_FILE='@file',
-> MASTER_LOG_POS=@pos;
Once this has been done, you can issue a
START SLAVE statement on MySQL
server F, and any missing updates originating from server B will
be replicated to server F.
User Comments
Add your own comment.